연결 만들기 또는 편집 create-or-edit-a-connection
연결 생성과 편집 워크플로 환경은 모든 데이터 세트 및 연결 구성 설정을 보조 워크플로와 함께 화면 중앙으로 가져옵니다. 상세한 데이터 세트 선택, 구성 및 검토 경험을 제공합니다. 잘못된 연결 구성의 위험을 줄이기 위해 데이터 세트 유형, 크기, 스키마, 데이터 세트 ID, 배치 상태, 채우기 상태, ID 등과 같은 중요한 정보를 제공할 수 있습니다. 다음은 기능에 대한 개요입니다.
- 연결을 생성할 때 롤링 데이터 보존 기간을 활성화할 수 있습니다.
- 연결에서 데이터 세트를 추가하거나 제거할 수 있습니다. (데이터 세트를 제거하면 연결에서 데이터 세트가 제거되고 연결된 모든 데이터 보기 및 기본 Analysis Workspace 프로젝트에 영향을 미칩니다.)
- 각 데이터 세트에 대해 데이터 채우기를 활성화하고 요청할 수 있습니다.
- 예를 들어 데이터 세트를 편집하여 다른 채우기를 요청할 수 있습니다.
- 각 데이터 세트에 대한 기존 데이터를 가져올 수 있습니다.
데모 비디오를 보려면

사전 요구 사항
연결에 추가할 수 있는 데이터 세트의 최대 수는 100개로 제한됩니다. 혼합은 귀사에서 구매한 Customer Journey Analytics 패키지의 종류에 따라 다릅니다.
보유 중인 Customer Journey Analytics 패키지가 무엇인지 확실하지 않은 경우에는 귀사의 관리자에게 문의하십시오.
연결 만들기 create-connection
다음에 대한 연결 만들기:
- Customer Journey Analytics에서 상단 메뉴의 데이터 관리에서(선택 사항) 연결을 선택합니다.
- 새 연결 만들기를 선택합니다.
이제 연결의 세부 정보를 편집할 수 있습니다.
연결 편집 edit-connection
연결 편집 방법은 라이선스가 부여된 Customer Journey Analytics 패키지에 따라 다릅니다.
Customer Journey Analytics
연결 > 연결 이름화면에서 다음을 수행합니다.

-
연결 설정을 구성합니다.
table 0-row-2 1-row-2 2-row-2 3-row-2 4-row-2 5-row-2 6-row-2 설정 설명 연결 이름 연결의 고유한 이름을 입력합니다. 연결 설명 이 연결의 목적에 대해 설명합니다. 태그 태그를 지정하여 연결에 태그를 추가하면 해당 태그를 사용하여 이후 단계에서 연결을 검색할 수 있습니다. 롤링 데이터 기간 활성화 이 확인란이 선택되어 있으면 Customer Journey Analytics 데이터 보존을 연결 수준에서 개월(1개월, 3개월, 6개월 등) 단위의 롤링 기간으로 정의할 수 있습니다.
데이터 보존은 이벤트 데이터 세트 타임스탬프를 기반으로 하며 이벤트 데이터 세트에만 적용됩니다. 적용 가능한 타임스탬프가 없기 때문에 프로필 또는 조회 데이터 세트에 대한 롤링 데이터 기간 설정이 없습니다. 그러나 연결에 프로필 또는 조회 데이터 세트(하나 이상의 이벤트 데이터 세트 제외)가 포함된 경우 해당 데이터는 동일한 기간 동안 유지됩니다.
주요 이점은 적용 가능하고 유용한 데이터에 대해서만 저장하거나 보고하고 더 이상 유용하지 않은 오래된 데이터를 삭제한다는 것입니다. 계약 한도를 유지하고 초과 비용의 위험을 줄이는 데 도움이 됩니다.
- 기본값(선택 해제)을 그대로 두면 보존 기간이 Adobe Experience Platform 데이터 보존 설정으로 대체됩니다. Experience Platform에 25개월 분량의 데이터가 있는 경우 Customer Journey Analytics는 채우기를 통해 25개월 분량의 데이터를 받습니다. Experience Platform에서 이러한 개월 중 10개월을 삭제하면 Customer Journey Analytics는 나머지 15개월을 유지합니다.
- 롤링 데이터 기간을 사용하는 경우, 개월 수 선택에서 롤링 데이터 기간을 사용하는 개월 수를 지정합니다.
샌드박스 연결을 만들 데이터 세트가 포함된 Experience Platform의 샌드박스를 선택합니다.
Adobe Experience Platform은 디지털 경험 애플리케이션을 개발하고 발전시키는 데 도움이 되는 단일 Platform 인스턴스를 별도의 가상 환경으로 분할하는 샌드박스를 제공합니다. 샌드박스를 데이터 세트가 포함된 “데이터 사일로”로 간주할 수 있습니다. 샌드박스는 데이터 세트에 대한 액세스를 제어하는 데 사용됩니다.
샌드박스를 선택하면 왼쪽 레일에 해당 샌드박스에서 가져올 수 있는 모든 데이터 세트가 표시됩니다.
데이터 세트 추가 데이터 세트를 추가하려면 
구성한 데이터 세트에 대해 데이터 세트 테이블에는 다음 열이 표시됩니다.
table 0-row-2 1-row-2 2-row-2 3-row-2 4-row-2 5-row-2 6-row-2 7-row-2 8-row-2 9-row-2 10-row-2 11-row-2 12-row-2 13-row-2 14-row-2 열 설명 데이터 세트 이름 Customer Journey Analytics으로 가져올 데이터 세트를 한 개 이상 선택하고 추가를 선택합니다.
(선택할 데이터 세트가 여러 개인 경우 데이터 세트 목록 위에 있는 데이터 세트 검색 막대를 사용하여 올바른 데이터 세트를 검색할 수 있습니다.)

선택한 데이터 세트에 대한 컨텍스트 메뉴를 열려면
-

-

-

마지막으로 업데이트됨 이벤트 데이터 세트의 경우에만 이 설정이 Experience Platform의 이벤트 기반 스키마에서 기본 타임스탬프 필드로 자동 설정됩니다. “N/A”는 이 데이터 세트에 데이터가 없음을 의미합니다. 레코드 수 Experience Platform의 데이터 세트에 대한 지난달의 총 레코드입니다. 스키마 Adobe Experience Platform에서 데이터 세트를 만드는 데 사용한 스키마입니다. 데이터 세트 유형 이 연결에 추가한 각 데이터 세트에 대해 가져오는 데이터를 기반으로 데이터 세트 유형을 Customer Journey Analytics에서 자동으로 설정합니다. 이벤트 데이터, 프로필 데이터 및 조회 데이터의 3가지 데이터 세트 유형이 있습니다. 데이터 세트 유형에 대한 설명은 아래 테이블을 참조하십시오. 결합됨 데이터 세트가 연결 UI에서 결합에 대해 활성화되면 값은 true입니다. 그렇지 않으면 값이 false입니다. 결합 절차 요청의 결과로 생성된 결합된 데이터 세트는 이 테이블에서 결합된 것으로 식별되지 않으며 기본적으로 false 값을 갖습니다. 세부 기간 데이터 세트의 데이터 세부 기간입니다. 요약 데이터 세트에만 적용됩니다. 데이터 소스 유형 데이터 세트의 데이터 소스 유형입니다. 요약 데이터 세트에 해당되지 않습니다. 개인 ID 데이터 세트에 대한 개인 기반 보고를 지원하는 데 사용되는 개인 ID입니다. 키 조회 데이터 세트에 사용되는 키입니다. 일치하는 키 조회 데이터 세트에 사용되는 일치하는 키입니다. 새 데이터 가져오기 데이터 세트에 대한 새 데이터 가져오기 상태:


채우기 데이터 데이터 세트의 채우기 데이터 상태.



Customer Journey Analytics B2B Edition
[B2B Edition]{class="badge informative" title="Customer Journey Analytics B2B Edition"}
연결 > 연결 이름화면에서 다음을 수행합니다.

-
연결 설정을 구성합니다.
table 0-row-2 1-row-2 2-row-2 3-row-2 4-row-2 5-row-2 6-row-2 7-row-2 8-row-2 설정 설명 연결 이름 연결의 고유한 이름을 입력합니다. 연결 설명 이 연결의 목적에 대해 설명합니다. 태그 태그를 지정하여 연결에 태그를 추가하면 해당 태그를 사용하여 이후 단계에서 연결을 검색할 수 있습니다. 기본 ID 연결에 적합한 기본 ID를 선택합니다.
- B2C 시나리오에서 일반적으로 사용하는 개인 기반 연결의 경우,

- B2B 시나리오에서 일반적으로 사용하는 계정 기반 연결을 위한

연결에 데이터 세트를 하나 이상 추가하는 즉시 기본 ID를 더 이상 변경할 수 없습니다.
기본 ID를 선택하면 연결의 개인 기반 또는 계정 기반 여부가 정의됩니다. 연결 기반은 특정 데이터 세트 유형에 사용할 수 있는 설정을 결정합니다.선택 가능한 컨테이너 - 글로벌 계정: 연결에서 글로벌 계정의 구성을 활성화합니다.
- 기회: 연결에서 기회의 구성을 활성화합니다.
- 구매 그룹: 연결에서 구매 그룹의 구성을 활성화합니다.
샌드박스 연결을 만들 데이터 세트가 포함된 Experience Platform의 샌드박스를 선택합니다.
Adobe Experience Platform은 디지털 경험 애플리케이션을 개발하고 발전시키는 데 도움이 되는 단일 Platform 인스턴스를 별도의 가상 환경으로 분할하는 샌드박스를 제공합니다. 샌드박스를 데이터 세트가 포함된 “데이터 사일로”로 간주할 수 있습니다. 샌드박스는 데이터 세트에 대한 액세스를 제어하는 데 사용됩니다.
샌드박스를 선택하면 왼쪽 레일에 해당 샌드박스에서 가져올 수 있는 모든 데이터 세트가 표시됩니다.
롤링 데이터 기간 활성화 이 확인란이 선택되어 있으면 Customer Journey Analytics 데이터 보존을 연결 수준에서 개월(1개월, 3개월, 6개월 등) 단위의 롤링 기간으로 정의할 수 있습니다.
데이터 보존은 이벤트 데이터 세트 타임스탬프를 기반으로 하며 이벤트 데이터 세트에만 적용됩니다. 적용 가능한 타임스탬프가 없기 때문에 프로필 또는 조회 데이터 세트에 대한 롤링 데이터 기간 설정이 없습니다. 그러나 연결에 프로필 또는 조회 데이터 세트(하나 이상의 이벤트 데이터 세트 제외)가 포함된 경우 해당 데이터는 동일한 기간 동안 유지됩니다.
주요 이점은 적용 가능하고 유용한 데이터에 대해서만 저장하거나 보고하고 더 이상 유용하지 않은 오래된 데이터를 삭제한다는 것입니다. 계약 한도를 유지하고 초과 비용의 위험을 줄이는 데 도움이 됩니다.
- 기본값(선택 해제)을 그대로 두면 보존 기간이 Adobe Experience Platform 데이터 보존 설정으로 대체됩니다. Experience Platform에 25개월 분량의 데이터가 있는 경우 Customer Journey Analytics는 채우기를 통해 25개월 분량의 데이터를 받습니다. Platform에서 이러한 개월 중 10개월을 삭제하면 Customer Journey Analytics는 나머지 15개월을 유지합니다.
- 롤링 데이터 기간을 사용하는 경우, 개월 수 선택에서 롤링 데이터 기간을 사용하는 개월 수를 지정합니다.
데이터 세트 추가 데이터 세트를 추가하려면 구성한 데이터 세트에 대해 데이터 세트 테이블에는 다음 열이 표시됩니다.
table 0-row-2 1-row-2 2-row-2 3-row-2 4-row-2 5-row-2 6-row-2 7-row-2 8-row-2 9-row-2 10-row-2 11-row-2 12-row-2 13-row-2 14-row-2 15-row-2 16-row-2 17-row-2 열 설명 데이터 세트 이름 Customer Journey Analytics으로 가져올 데이터 세트를 한 개 이상 선택하고 추가를 선택합니다.
(선택할 데이터 세트가 여러 개인 경우 데이터 세트 목록 위에 있는 데이터 세트 검색 막대를 사용하여 올바른 데이터 세트를 검색할 수 있습니다.)
선택한 데이터 세트에 대한 컨텍스트 메뉴를 열려면
-
-
-
마지막으로 업데이트됨 이벤트 데이터 세트의 경우에만 이 설정이 Experience Platform의 이벤트 기반 스키마에서 기본 타임스탬프 필드로 자동 설정됩니다. “N/A”는 이 데이터 세트에 데이터가 없음을 의미합니다. 레코드 수 Experience Platform의 데이터 세트에 대한 지난달의 총 레코드입니다. 스키마 Adobe Experience Platform에서 데이터 세트를 만드는 데 사용한 스키마입니다. 데이터 세트 유형 이 연결에 추가한 각 데이터 세트에 대해 가져오는 데이터를 기반으로 데이터 세트 유형을 Customer Journey Analytics에서 자동으로 설정합니다. 세부 기간 데이터 세트의 데이터 세부 기간입니다. 요약 데이터 세트에만 적용됩니다. 데이터 소스 유형 데이터 세트의 데이터 소스 유형입니다. 요약 데이터 세트에 해당되지 않습니다. 계정 ID (계정 기반 연결에만 표시됨) 데이터 세트에 대한 계정 기반 보고를 지원하는 데 사용되는 계정 ID입니다. 글로벌 계정 ID (계정 기반 연결에만 표시됨) 데이터 세트에 대한 계정 기반 보고를 지원하는 데 사용되는 글로벌 계정 ID입니다. 구매 그룹 ID (계정 기반 연결에서만 표시됨) 구매 그룹 데이터를 조회하는 데 사용되는 구매 그룹 ID입니다. 기회 ID (계정 기반 연결에만 표시됨) 기회 데이터를 조회하는 데 사용되는 기회 ID입니다. 개인 ID 데이터 세트에 대한 개인 기반 보고를 지원하는 데 사용되는 개인 ID입니다. 키 조회 데이터 세트에 사용되는 키입니다. 일치하는 키 조회 데이터 세트에 사용되는 일치하는 키입니다. 새 데이터 가져오기 데이터 세트에 대한 새 데이터 가져오기 상태:
채우기 데이터 데이터 세트의 채우기 데이터 상태.
- B2C 시나리오에서 일반적으로 사용하는 개인 기반 연결의 경우,
데이터 세트 datasets
연결 워크플로의 일부로 하나 이상의 데이터 세트를 추가하거나 기존 데이터 세트를 편집합니다.
null 값으로 대체됩니다.1900년 이전의 타임스탬프 값이 있는 이벤트 또는 요약 데이터 세트의 행이 수집에서 삭제됩니다.
데이터 세트 유형 dataset-types
이 연결에 추가한 각 데이터 세트에 대해 가져오는 데이터를 기반으로 데이터 세트 유형을 Customer Journey Analytics에서 자동으로 설정합니다.
데이터 세트 유형에는 각각 해당 XDM 기반 스키마를 기반으로 하는 이벤트 데이터, 프로필 데이터, 조회 데이터 및 요약 데이터가 있습니다.
프로필, 조회 및 이벤트 데이터 세트(후자의 경우 항상 지원됨) 등 모든 데이터 세트 유형 내의 필드 조회로 데이터세트를 추가할 수 있습니다. 이 추가 기능은 B2B 등 복잡한 데이터 모델을 지원하는 Customer Journey Analytics의 기능을 확장합니다. 이 데이터는 이벤트, 프로필 또는 조회 데이터에 있는 값이나 키를 찾는 데 사용됩니다. 최대 3개 조회 수준을 추가할 수 있습니다. 예를 들어 이벤트 데이터의 숫자 ID를 제품 이름에 매핑하는 조회 데이터를 업로드할 수 있습니다. 사례에 대해서는 B2B 예시를 참조하십시오.
참고:
또는 위에 나열된 데이터 세트 유형은 일반 XDM 기반 스키마 대신 애드 혹이나 관계형 스키마를 기반으로 할 수 있습니다.
데이터 세트 추가
연결을 만들거나 편집할 때 하나 이상의 Experience Platform 데이터 세트를 추가할 수 있습니다.
사용자 기반 연결용
-
연결 > 연결 이름 인터페이스에서
-
➊ 데이터 세트 선택 단계에서는 Experience Platform 데이터 세트의 목록이 표시됩니다.

각 데이터 세트에 대해, 목록은 다음과 같이 나타납니다.
table 0-row-2 1-row-2 2-row-2 3-row-2 4-row-2 5-row-2 6-row-2 7-row-2 열 설명 데이터 세트 데이터 세트의 이름입니다. Experience Platform의 데이터 세트로 사용자를 이동할 이름을 선택합니다. 데이터 세트에 대한 더 자세한 내용이 포함된 팝업이 표시되도록 하려면 
데이터 세트 유형 데이터 세트 유형: 이벤트, 프로필, 조회, 요약, 임시 또는 관계형 레코드 수 Experience Platform의 데이터 세트에 대한 지난달의 총 레코드입니다. 스키마 데이터 세트의 스키마입니다. Experience Platform의 스키마로 사용자를 이동할 이름을 선택합니다. 마지막 배치 Experience Platform에서 수집된 마지막 배치의 상태입니다. 더 자세한 내용은 배치 상태를 참조하시기 바랍니다. 데이터 세트 ID 데이터 세트의 ID입니다. 마지막으로 업데이트됨 데이터 세트에서 마지막으로 업데이트된 타임스탬프입니다. - 데이터 세트 목록에 표시되는 열을 변경하려면

- 특정 데이터 세트를 검색하려면

- 선택한 데이터 세트 표시 또는 숨기기 간 전환하려면

- 선택한 데이터 세트 목록에서 데이터 세트를 제거하려면

- 데이터 세트에 대한 세부 정보를 표시하려면

- 데이터 세트 목록에 표시되는 열을 변경하려면
-
하나 이상의 데이터 세트를 선택하고 다음을 선택합니다. 하나 이상의 이벤트 또는 요약 데이터 세트가 연결의 일부가 되어야 합니다.
-
데이터 세트 추가 대화 상자의 ➋ 데이터 세트 설정 단계에서 선택한 데이터 세트 각각의 설정을 하나씩 구성합니다.

- 연결에서 데이터 집합을 제거하려면

- 뒤로 돌아가려면 뒤로를 선택하세요.
- 연결에 데이터 세트 추가를 취소하려면 취소를 선택하십시오.
- 연결에서 데이터 집합을 제거하려면
-
계속하려면 선택한 데이터 세트에 필요한 모든 설정을 지정해야 합니다. 필수 입력이 누락된 경우 해당 필수 입력이 누락된 특정 유형의 데이터 세트 수를 나타내는 빨간색 숫자가 표시됩니다.

-
❸ 데이터 세트 미리 보기에서는 최근에 수집된 데이터의 간단한 데이터 집합을 기반으로 하는 각 데이터 세트에 대한 미리 보기를 볼 수 있습니다.

-
테이블의 각 열에 대한 네임스페이스를 표시하려면 열 네임스페이스 표시를 사용하도록 설정하십시오.
-
샘플 데이터를 검색하려면
-
표시할 열을 구성하려면

테이블 사용자 지정대화 상자에서:- 테이블에 표시할 열을 선택합니다.
- 적용을 선택하여 선택 항목을 적용하거나 취소을 선택하여 선택 항목을 취소합니다.
-
배열 또는 개체 데이터가 포함된 열의 데이터를 표시하려면 값을(를) 선택하십시오.
데이터 집합 정보 창에는 데이터 집합에 대한 세부 정보가 표시됩니다. 스키마 또는 데이터 세트의 값을 선택하여 새 브라우저 탭에서 Experience Platform의 관련 인터페이스를 엽니다.
- 연결에서 데이터 집합을 제거하려면
- 뒤로 돌아가려면 뒤로를 선택하세요.
- 연결에 데이터 세트 추가를 취소하려면 취소를 선택하십시오.
-
-
구성된 데이터 세트를 연결에 추가하려면 데이터 세트 추가를 선택합니다.
계정 기반 연결용
연결을 만들거나 편집할 때 하나 이상의 Experience Platform 데이터 세트를 추가할 수 있습니다.
-
연결 > 연결 이름 인터페이스에서
-
➊ 데이터 세트 선택 단계에서는 Experience Platform 데이터 세트의 목록이 표시됩니다.
각 데이터 세트에 대해, 목록은 다음과 같이 나타납니다.
table 0-row-2 1-row-2 2-row-2 3-row-2 4-row-2 5-row-2 6-row-2 7-row-2 열 설명 데이터 세트 데이터 세트의 이름입니다. Experience Platform의 데이터 세트로 사용자를 이동할 이름을 선택합니다. 데이터 세트에 대한 더 자세한 내용이 포함된 팝업이 표시되도록 하려면 데이터 세트 유형 데이터 세트 유형: 이벤트, 프로필, 조회, 요약, 임시 또는 관계형 레코드 수 Experience Platform의 데이터 세트에 대한 지난달의 총 레코드입니다. 스키마 데이터 세트의 스키마입니다. Experience Platform의 스키마로 사용자를 이동할 이름을 선택합니다. 마지막 배치 Experience Platform에서 수집된 마지막 배치의 상태입니다. 더 자세한 내용은 배치 상태를 참조하시기 바랍니다. 데이터 세트 ID 데이터 세트의 ID입니다. 마지막으로 업데이트됨 데이터 세트에서 마지막으로 업데이트된 타임스탬프입니다. - 데이터 세트 목록에 표시되는 열을 변경하려면
- 특정 데이터 세트를 검색하려면
- 선택한 데이터 세트 표시 또는 숨기기 간 전환하려면
- 선택한 데이터 세트 목록에서 데이터 세트를 제거하려면
- 데이터 세트에 대한 세부 정보를 표시하려면
- 데이터 세트 목록에 표시되는 열을 변경하려면
-
하나 이상의 데이터 세트를 선택하고 다음을 선택합니다. 하나 이상의 이벤트 또는 요약 데이터 세트가 연결의 일부가 되어야 합니다.
-
데이터 세트 추가 대화 상자의 ➋ 데이터 세트 설정 단계에서 선택한 데이터 세트 각각의 설정을 하나씩 구성합니다.

-
구성된 데이터 세트를 연결에 추가하려면 데이터 세트 추가를 선택합니다. 추가하려는 각 데이터 세트에 대한 모든 필수 설정을 제공하지 않은 경우, 알림을 받습니다.
또는 취소를 선택하여 연결에 대한 데이터 세트 추가를 취소할 수 있습니다. 또는 뒤로를 선택하여 ➊ 데이터 세트 선택 단계로 돌아갑니다.
데이터 세트 편집
연결에 대해 이미 구성된 데이터 세트를 편집하려면 연결 > 연결 이름 인터페이스에서 다음을 수행합니다.
사용자 기반 연결용
-
-
편집할 데이터 세트 테이블에 나열된 데이터 세트에 대해
-
-
❶ 데이터 집합 설정에서 데이터 집합 편집: 데이터 집합 이름대화 상자에서 데이터 집합 설정을 구성하십시오.

변경하는 경우 계속하기 전에 데이터 세트에 필요한 모든 설정을 지정해야 합니다. 필수 입력이 누락된 경우 계속할 수 없습니다.
note NOTE 저장된 연결의 일부인 애드 혹 또는 관계형 데이터 세트에 대한 데이터 세트 유형, 개인 ID, ID 네임스페이스 및 타임스탬프를 편집할 수 없습니다. 이러한 설정을 변경하려면 다음과 같은 작업을 수행합니다. - 연결에서 기존의 애드 혹 또는 관계형 데이터 세트를 삭제합니다.
- 업데이트된 설정이 있는 동일한 데이터 세트를 연결에 추가합니다.
연결에서 데이터 집합을 제거하려면
데이터 집합에 필요한 설정을 모두 구성했으면 다음을 선택합니다.
-
❷ 데이터 세트 미리 보기에서는 최근에 수집된 데이터의 간단한 데이터 집합을 기반으로 하는 각 데이터 세트에 대한 미리 보기를 볼 수 있습니다.
-
테이블의 각 열에 대한 네임스페이스를 표시하려면 열 네임스페이스 표시를 사용하도록 설정하십시오.
-
샘플 데이터를 검색하려면
-
표시할 열을 구성하려면
테이블 사용자 지정대화 상자에서:- 테이블에 표시할 열을 선택합니다.
- 적용을 선택하여 선택 항목을 적용하거나 취소을 선택하여 선택 항목을 취소합니다.
-
배열 또는 개체 데이터가 포함된 열의 데이터를 표시하려면 값을(를) 선택하십시오.
데이터 집합 정보 창에는 데이터 집합에 대한 세부 정보가 표시됩니다. 스키마 또는 데이터 세트의 값을 선택하여 새 브라우저 탭에서 Experience Platform의 관련 인터페이스를 엽니다.
- 연결에서 데이터 집합을 제거하려면
- 뒤로 돌아가려면 뒤로를 선택하세요.
- 연결에 데이터 세트 추가를 취소하려면 취소를 선택하십시오.
-
-
데이터 세트 설정을 적용하려면 적용을 선택합니다. 취소하려면 취소를 선택합니다.
계정 기반 연결용
-
-
편집할 데이터 세트 테이블에 나열된 데이터 세트에 대해
-
-
데이터 세트 편집: 데이터 세트 이름대화 상자에서 데이터 세트 설정을 구성합니다.

note NOTE 저장된 연결의 일부인 애드 혹 또는 관계형 데이터 세트에 대한 데이터 세트 유형, 개인 ID, ID 네임스페이스 및 타임스탬프를 편집할 수 없습니다. 이러한 설정을 변경하려면 다음과 같은 작업을 수행합니다. - 연결에서 기존의 애드 혹 또는 관계형 데이터 세트를 삭제합니다.
- 업데이트된 설정이 있는 동일한 데이터 세트를 연결에 추가합니다.
-
데이터 세트 설정을 적용하려면 적용을 선택합니다. 취소하려면 취소를 선택합니다.
데이터 세트 설정
데이터 세트를 추가하거나 기존 데이터 세트를 편집할 때 각 데이터 세트에 대한 데이터 세트 설정을 구성합니다. 사용 가능한 설정은 데이터 세트 유형에 따라 다르며, 일부 데이터 세트 유형의 경우 연결 유형(개인 기반 또는 [B2B Edition]{class="badge informative" title="Customer Journey Analytics B2B Edition"} 계정 기반)에 따라 다릅니다.
모든 데이터 세트 및 데이터 세트 유형에는 새 데이터를 가져오고 다시 채우기를 요청할지 여부와 같은 일반 설정 및 세부 정보가 있습니다.
이벤트 데이터 세트
이벤트 데이터 세트에 대한 특정 설정은 연결 유형에 따라 다릅니다.
개인 기반 연결

개인 기반 연결의 이벤트 데이터 세트에 대해 다음을 지정할 수 있습니다.
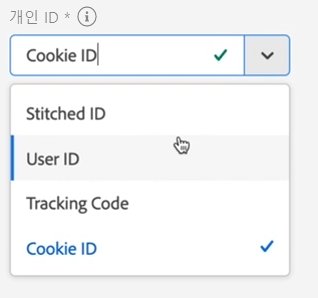
사용 가능한 ID의 드롭다운 메뉴에서 개인 ID를 선택합니다. 해당 ID는 Experience Platform의 데이터 세트 스키마에 정의되어 있습니다. ID 맵을 개인 ID로 사용하는 방법에 대한 자세한 내용은 ID 맵을 개인 ID로 사용을 참조하십시오.
선택할 개인 ID가 없는 경우, 스키마에 정의된 개인 ID가 없음을 의미합니다. 자세한 내용은 UI에서 ID 필드 정의를 참조하십시오.
선택한 개인 ID의 값은 대소문자를 구분하는 것으로 간주됩니다. 예를 들어 abc123 및 ABC123은 서로 다른 두 값입니다.
레코드에 이벤트 데이터 세트의 개인 ID로 선택한 ID에 대한 값이 없는 경우 레코드를 건너뜁니다.
데이터 소스 유형을 선택합니다. 데이터 소스 유형에는 다음이 포함됩니다.
- 웹 데이터
- 모바일 앱 데이터
- POS 데이터
- CRM 데이터
- 설문 조사 데이터
- 콜 센터 데이터
- 제품 데이터
- 계정 데이터
- 트랜잭션 데이터
- 고객 피드백 데이터
- 기타
이 필드를 사용하여 사용 중인 데이터 소스 유형을 조사합니다.
계정 기반 연결
[B2B Edition]{class="badge informative" title="Customer Journey Analytics B2B Edition"}
계정 기반 연결의 이벤트 데이터 세트에 대해 다음을 지정할 수 있습니다.

글로벌 계정을 연결에 컨테이너로 추가한 경우 적용할 수 있습니다.
Experience Platform의 데이터 세트 스키마에 정의된 사용 가능한 비ID 또는 비개인 ID 필드에서 글로벌 계정 ID(계정의 고유 식별자)를 선택합니다. 포함된 값은 개인 대 계정 데이터 세트에서 관련 계정 ID 정보를 사용할 수 없을 때마다 행 수준에서 고유한 계정 식별자로 사용됩니다.
레코드에 이벤트 데이터 세트의 계정 ID로 선택한 ID에 대한 값이 없는 경우 레코드를 건너뜁니다.
사용 가능한 ID의 드롭다운 메뉴에서 개인 ID를 선택합니다. 이러한 ID는 Experience Platform의 데이터 세트 스키마에 정의되어 있습니다. ID 맵을 개인 ID로 사용하는 방법에 대한 자세한 내용은 ID 맵을 개인 ID로 사용을 참조하십시오.
선택할 개인 ID가 없는 경우 하나 이상의 개인 ID가 스키마에 정의되어 있지 않음을 의미합니다. 자세한 내용은 UI에서 ID 필드 정의를 참조하십시오.
선택한 개인 ID의 값은 대소문자를 구분하는 것으로 간주됩니다. 예를 들어 abc123 및 ABC123은 서로 다른 두 값입니다.
데이터 소스 유형을 선택합니다. 데이터 소스 유형에는 다음이 포함됩니다.
- 웹 데이터
- 모바일 앱 데이터
- POS 데이터
- CRM 데이터
- 설문 조사 데이터
- 콜 센터 데이터
- 제품 데이터
- 계정 데이터
- 트랜잭션 데이터
- 고객 피드백 데이터
- 기타
이 필드를 사용하여 사용 중인 데이터 소스 유형을 조사합니다.
프로필 데이터 세트
프로필 데이터 세트에 대한 특정 설정은 연결 유형에 따라 다릅니다.
개인 기반 연결

개인 기반 연결의 프로필 데이터 세트에 대해 다음을 지정합니다.
사용 가능한 ID의 드롭다운 메뉴에서 개인 ID를 선택합니다. 해당 ID는 Experience Platform의 데이터 세트 스키마에 정의되어 있습니다. ID 맵을 개인 ID로 사용하는 방법에 대한 자세한 내용은 ID 맵을 개인 ID로 사용을 참조하십시오.
선택할 개인 ID가 없는 경우, 스키마에 정의된 개인 ID가 없는 것입니다. 자세한 내용은 UI에서 ID 필드 정의를 참조하십시오.
선택한 개인 ID의 값은 대소문자를 구분하는 것으로 간주됩니다. 예를 들어 abc123 및 ABC123은 서로 다른 두 값입니다.
레코드에 프로필 데이터 세트의 개인 ID로 선택한 ID에 대한 값이 없는 경우 레코드를 건너뜁니다.
데이터 소스 유형을 선택합니다. 데이터 소스 유형에는 다음이 포함됩니다.
- 웹 데이터
- 모바일 앱 데이터
- POS 데이터
- CRM 데이터
- 설문 조사 데이터
- 콜 센터 데이터
- 제품 데이터
- 계정 데이터
- 트랜잭션 데이터
- 고객 피드백 데이터
- 기타
이 필드를 사용하여 사용 중인 데이터 소스 유형을 조사합니다.
계정 기반 연결

계정 기반 연결의 프로필 데이터 세트에 대해 다음을 지정합니다.
사용 가능한 ID의 드롭다운 메뉴에서 개인 ID를 선택합니다. 해당 ID는 Experience Platform의 데이터 세트 스키마에 정의되어 있습니다. ID 맵을 개인 ID로 사용하는 방법에 대한 자세한 내용은 ID 맵을 개인 ID로 사용을 참조하십시오.
선택할 개인 ID가 없는 경우, 스키마에 정의된 개인 ID가 없는 것입니다. 자세한 내용은 UI에서 ID 필드 정의를 참조하십시오.
선택한 개인 ID의 값은 대소문자를 구분하는 것으로 간주됩니다. 예를 들어 abc123 및 ABC123은 서로 다른 두 값입니다.
레코드에 프로필 데이터 세트의 개인 ID로 선택한 ID에 대한 값이 없는 경우 레코드를 건너뜁니다.
데이터 소스 유형을 선택합니다. 데이터 소스 유형에는 다음이 포함됩니다.
- 웹 데이터
- 모바일 앱 데이터
- POS 데이터
- CRM 데이터
- 설문 조사 데이터
- 콜 센터 데이터
- 제품 데이터
- 계정 데이터
- 트랜잭션 데이터
- 고객 피드백 데이터
- 기타
이 필드를 사용하여 사용 중인 데이터 소스 유형을 조사합니다.
조회 데이터 세트
조회 데이터 세트에 대한 특정 설정은 연결 유형에 따라 다릅니다.
개인 기반 연결

개인 기반 연결의 조회 데이터 세트에 대해 다음을 지정합니다.
조회 데이터 세트에 사용할 키입니다.
레코드에 조회 데이터 세트에 대해 선택한 키의 값이 없는 경우, 레코드를 건너뜁니다.
데이터 소스 유형을 선택합니다. 데이터 소스 유형에는 다음이 포함됩니다.
- 웹 데이터
- 모바일 앱 데이터
- POS 데이터
- CRM 데이터
- 설문 조사 데이터
- 콜 센터 데이터
- 제품 데이터
- 계정 데이터
- 트랜잭션 데이터
- 고객 피드백 데이터
- 기타
이 필드를 사용하여 사용 중인 데이터 소스 유형을 조사합니다.
계정 기반 연결
[B2B Edition]{class="badge informative" title="Customer Journey Analytics B2B Edition"}

계정 기반 연결의 조회 데이터 세트에 대해 다음을 지정할 수 있습니다.
조회 데이터 세트에 사용할 키입니다.
레코드에 조회 데이터 세트에 대해 선택한 키의 값이 없는 경우, 레코드를 건너뜁니다.
이벤트 데이터 세트 중 하나에 연결할 일치하는 키입니다. 이 목록이 비어 있다면 이벤트 데이터 세트를 추가하거나 구성하지 않았을 가능성이 높습니다.
선택한 일치하는 키 유형에 따라 적절한 값을 선택합니다.
- 필드로 일치:

이벤트 데이터 세트 중 하나에 연결하려면 일치하는 키 드롭다운 메뉴에서 필드를 선택합니다. 이 목록이 비어 있다면 이벤트 데이터 세트를 추가하거나 구성하지 않았을 가능성이 높습니다. - 컨테이너로 일치:

이벤트 데이터 세트 중 하나에 연결하는 데 사용할 일치하는 키 드롭다운 메뉴에서 컨테이너를 선택합니다. 연결 설정의 일부로 포함한 컨테이너에 따라 선택 가능한 컨테이너가 결정됩니다.
요약 데이터 세트
요약 데이터 세트에 대한 특정 설정은 다음과 같습니다.
애드 혹 데이터 세트
애드 혹 데이터 세트에 대한 특정 설정은 다음과 같습니다.
애드 혹 스키마의 필드 중 하나 이상에 ID 레이블이 지정되고 ID 네임스페이스가 있는 경우에만 ID 네임스페이스에서 식별자를 선택할 수 있습니다.
DateTime 형식의 필드일 수 있습니다.레코드에 조회 데이터 세트에 대해 선택한 키의 값이 없는 경우, 레코드를 건너뜁니다.
관계형 데이터 세트
관계형 데이터 세트에 대한 특정 설정은 다음과 같습니다.
데이터 세트에 시계열 데이터가 포함되어 있는 경우, 가능한 값은 이벤트 및 요약입니다.
데이터 세트에 레코드 데이터가 포함되어 있는 경우, 가능한 값은 프로필 및 조회입니다.
레코드에 조회 데이터 세트에 대해 선택한 키의 값이 없는 경우, 레코드를 건너뜁니다.
일반 데이터 세트 설정 및 세부 정보
각 데이터 세트 유형에는 다음과 같은 공통 설정이 있습니다.
기존의 모든 데이터 다시 채우기를 활성화하여 기존의 모든 데이터를 다시 채웁니다.
특정 기간의 내역 데이터를 다시 채우려면 다시 채우기 요청을 선택합니다. 최대 10개의 데이터 세트 채우기 기간을 정의할 수 있습니다.
- 시작 및 종료 데이터를 입력하거나

- 대기열 다시 채우기를 선택하여 목록에 다시 채우기를 추가하거나 취소를 선택하여 취소합니다.
각 항목에 대해


다시 채우기 이후에는
- 각 데이터 세트를 개별적으로 채울 수 있습니다.
- 연결하는 데이터 세트에 추가된 새 데이터에 우선순위를 두므로 이 새 데이터의 지연 시간이 가장 짧습니다.
- 모든 채우기 (이전) 데이터는 더 느린 속도로 가져옵니다. 내역 데이터의 양은 지연 시간에 영향을 미칩니다.
- Analytics 소스 커넥터는 프로덕션 샌드박스의 경우 (크기에 상관없이) 최대 13개월의 데이터를 가져옵니다. 비프로덕션 샌드박스의 다시 채우기는 3개월로 제한됩니다.
- 프로덕션 샌드박스의 경우, 13개월보다 이전의 내역 채우기 데이터를 가져올 수 있는 추가 SKU에 대한 라이선스를 보유하고 있다면 Adobe에 문의하여 확장된 채우기를 요청하십시오.
가능한 상태 표시기는 다음과 같습니다.
- 성공
- X 채우기 처리
- 꺼짐
데이터 재수집
경우에 따라 하나 이상의 데이터 세트의 데이터를 연결로 재수집해야 합니다. 애드 혹 또는 관계형 데이터 세트의 경우, 삭제 후 데이터 세트를 다시 추가해야 합니다. 다른 데이터 세트의 경우, 설정을 업데이트할 수 있습니다. 이렇게 하려면 다음 작업을 수행하십시오.
-
데이터를 재수집할 데이터 세트:
-
다음 중 하나를 변경합니다.
- 이미 수집된 이벤트 데이터 세트에 대한 식별자(개인 ID, 계정 ID 또는 기타 ID)입니다.
- 이미 수집된 프로필 또는 조회 데이터 세트에 대한 키, 일치하는 키 또는 일치하는 키 유형(필드 또는 컨테이너)입니다.
또는 데이터 세트에서 기존 데이터 채우기 모두 채우기를 전환할 수 있습니다.
-
데이터 세트에 대한 변경 내용을 적용합니다.
-
-
연결을 저장합니다. 특정 데이터 세트에 대한 데이터가 재수집됩니다.
데이터 세트 삭제
데이터 세트를 삭제하면 삭제의 영향에 대한 알림이 표시됩니다. 데이터 세트를 삭제하면 관련된 모든 연결, 데이터 보기 및 프로젝트에 영향을 미칠 수 있습니다. 또한 연결에서 유일한 이벤트 또는 요약 데이터 세트를 삭제하면 다른 이벤트 또는 요약 데이터 세트를 추가하라는 메시지가 표시됩니다. 하나 이상의 이벤트 또는 요약 데이터 세트가 포함된 연결만 저장할 수 있습니다.
이전 채우기
인터페이스에서
연결 미리보기 preview
생성한 연결을 미리 보려면 연결 설정 대화 상자에서


이 미리보기에는 연결 구성을 나열하는 열이 일부 있습니다. 표시되는 열 유형은 개별 데이터 세트에 따라 다릅니다.
연결 맵
연결의 일부로 포함된 데이터 세트 간의 관계 맵을 보려면 연결 설정 대화 상자에서


이 맵을 사용하면 연결을 정의한 방법을 더 잘 이해할 수 있습니다. 컨테이너와 식별자를 사용하여 이벤트, 프로필, 조회 및 요약 데이터 세트 간의 관계를 설정하는 방법입니다.
숫자 필드를 조회 키 및 조회 값으로 사용 numeric
이 조회 기능은 비용 또는 이윤과 같은 숫자 필드를 문자열 기반 키 필드에 추가할 때 유용합니다. 숫자 값을 키 또는 값으로 조회에 포함할 수 있습니다. 조회 스키마에서는 제품 이름, COGS, 캠페인 마케팅 비용 또는 이윤과 같은 숫자 값을 연결할 수 있습니다. 다음은 Adobe Experience Platform의 조회 스키마 예제입니다.

이제 이러한 값을 Customer Journey Analytics 보고에 지표 또는 차원으로 가져오도록 지원합니다. 연결을 설정하고 조회 데이터 세트를 가져올 때 데이터 세트를 편집하여 키 및 일치하는 키를 선택할 수 있습니다.

이 연결을 기준으로 데이터 보기를 설정할 때 숫자 값을 데이터 보기에 구성 요소로 추가합니다. 이 데이터 보기를 기반으로 하는 프로젝트는 이러한 숫자 값을 보고할 수 있습니다.
ID 맵을 개인 ID로 사용 id-map
Customer Journey Analytics에서는 개인 ID로 ID 맵을 사용하는 기능을 지원합니다. ID 맵은 사용자의 키 값 쌍 업로드를 허용하는 맵 데이터 구조입니다. 키는 ID 네임스페이스이며, 값은 ID 값을 가지는 구조입니다. ID 맵은 업로드된 각 행/이벤트에 있으며 해당 행에 맞게 작성됩니다.
ID 맵은 ExperienceEvent XDM 클래스 기반의 스키마를 사용하는 데이터 세트에 사용 가능합니다. Customer Journey Analytics 연결에 이러한 데이터 세트를 포함하도록 선택하는 경우 필드를 기본 ID나 ID 맵으로 선택하는 옵션이 제공됩니다.

ID 맵을 선택하면 두 가지 추가 구성 옵션이 제공됩니다.
primary=true 속성으로 표시된 ID를 찾아 해당 행의 개인 ID로 사용합니다. 이 ID는 Experience Platform에서 파티셔닝에 사용하는 기본 키입니다. 이 ID는 Customer Journey Analytics 개인 ID로 사용하기에 가장 적합한 후보이기도 합니다(Customer Journey Analytics 연결에 데이터 세트가 구성되는 방법에 따라 다름).ID 맵의 극단적 사례 id-map-edge
이 테이블에서는 극단적 사례가 있을 때 이 사례들이 처리되는 방식을 두 가지 구성 옵션으로 보여 줍니다.


일일 평균 이벤트 수 계산 average-number
이 계산은 연결의 모든 데이터 세트에 대해 수행됩니다.
-
Adobe Experience Platform 쿼리 서비스로 이동하여 쿼리를 만듭니다.
이 쿼리의 형태는 다음과 같습니다.
code language-none Select AVG(A.total_events) from (Select DISTINCT COUNT (*) as total_events, date(TIMESTAMP) from analytics_demo_data GROUP BY 2 Having total_events>0) A;이 예에서 “analytics_demo_data”는 데이터 세트의 이름입니다.
-
Adobe Experience Platform에 있는 모든 데이터 세트를 표시하려면
Show Tables쿼리를 수행하십시오.