Crear Dynamic Datastream Configurations
De manera predeterminada, Adobe Experience Platform Edge Network envía todos los eventos que llegan a una secuencia de datos a todos los Experience Cloud servicios que ha habilitado para sus secuencias de datos. Según sus casos de uso, este puede no ser siempre el flujo de trabajo ideal.
Las configuraciones de flujo de datos dinámico solucionan esto mediante conjuntos de reglas que se definen para cada servicio habilitado para el flujo de datos, que controlan qué solución de Experience Cloud recibe cada tipo de datos.
Guía de Dynamic Datastream Configurations guide
Si es su primera vez en Dynamic Datastream Configurations o planea una implementación de producción, lea la guía completa antes de configurar las reglas. La guía cubre la taxonomía de eventos, las estrategias de conjuntos de datos, los casos de uso, las prácticas recomendadas y el enfoque de prueba.
- Información general: cómo se evalúan las reglas, la taxonomía de eventos y la exclusividad mutua con las invalidaciones del lado del cliente
- Lista de comprobación de requisitos previos y planificación: configuración del flujo de datos, preparación de esquemas y conjuntos de datos e inventario de eventos
- Patrones de configuración: primero se pueden procesar y después usar estrategias de primer conjunto de datos analíticas
- Casos de uso: seis escenarios de enrutamiento comunes con tablas de reglas de ejemplo
- Ejemplo completo: una implementación completa de comercio electrónico
- Prácticas recomendadas: diseño de reglas, estrategia de conjuntos de datos y directrices operativas
- Probar y validar: lista de comprobación de pruebas basadas en Assurance
- preguntas más frecuentes: preguntas comunes sobre el comportamiento de la regla y las interacciones del sistema
Requisitos previos prerequisites
Para crear una configuración dinámica para el conjunto de datos, deben cumplirse dos condiciones:
- Debe haber creado al menos un conjunto de datos para trabajar con él. Consulte la documentación sobre cómo crear un conjunto de datos para obtener información detallada.
- Debe tener al menos un servicio Experience Cloud agregado a su secuencia de datos. Consulte la documentación sobre cómo agregar un servicio a un conjunto de datos para obtener información detallada.
Después de crear una secuencia de datos y agregarle un servicio de Experience Cloud, puede crear una configuración dinámica.
Mecanismos de protección guardrails
Las configuraciones de flujo de datos dinámico tienen límites específicos y restricciones de rendimiento para garantizar un rendimiento óptimo del sistema y una eficiencia de procesamiento de datos. Al configurar reglas de flujo de datos dinámico, se aplican las siguientes protecciones:
Configuraciones dinámicas de flujo de datos frente a anulaciones de configuración de flujo de datos dynamic-versus-overrides
Las configuraciones dinámicas de secuencia de datos y las anulaciones de configuración de secuencia de datos son funcionalidades mutuamente exclusivas.
No puede usar Dynamic Datastream Configurations junto con invalidaciones de configuración de secuencia de datos. Debe elegir una o la otra.
Si habilita ambas, las invalidaciones de configuración tienen prioridad y el sistema ignora las reglas de Dynamic Datastream Configuration.
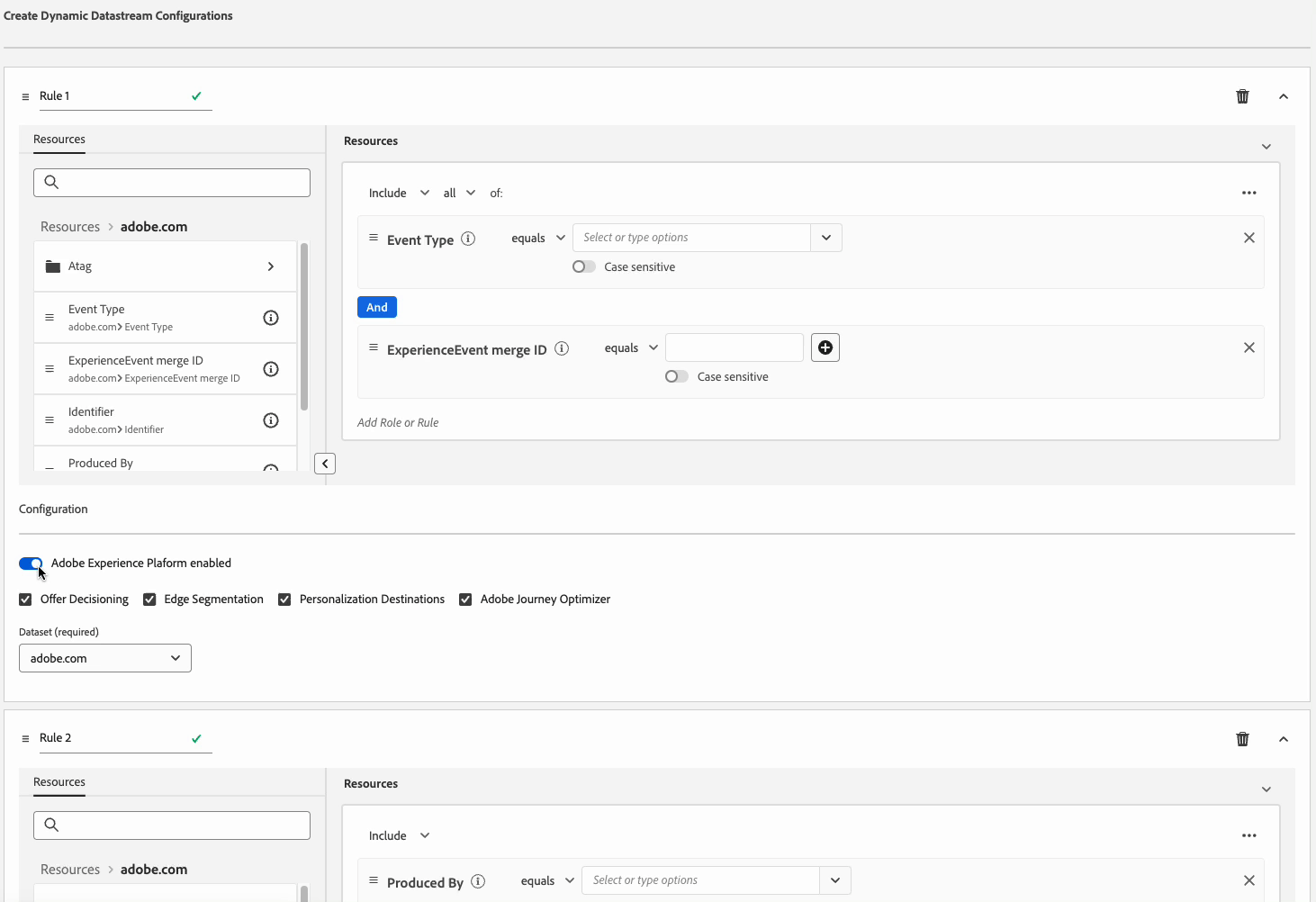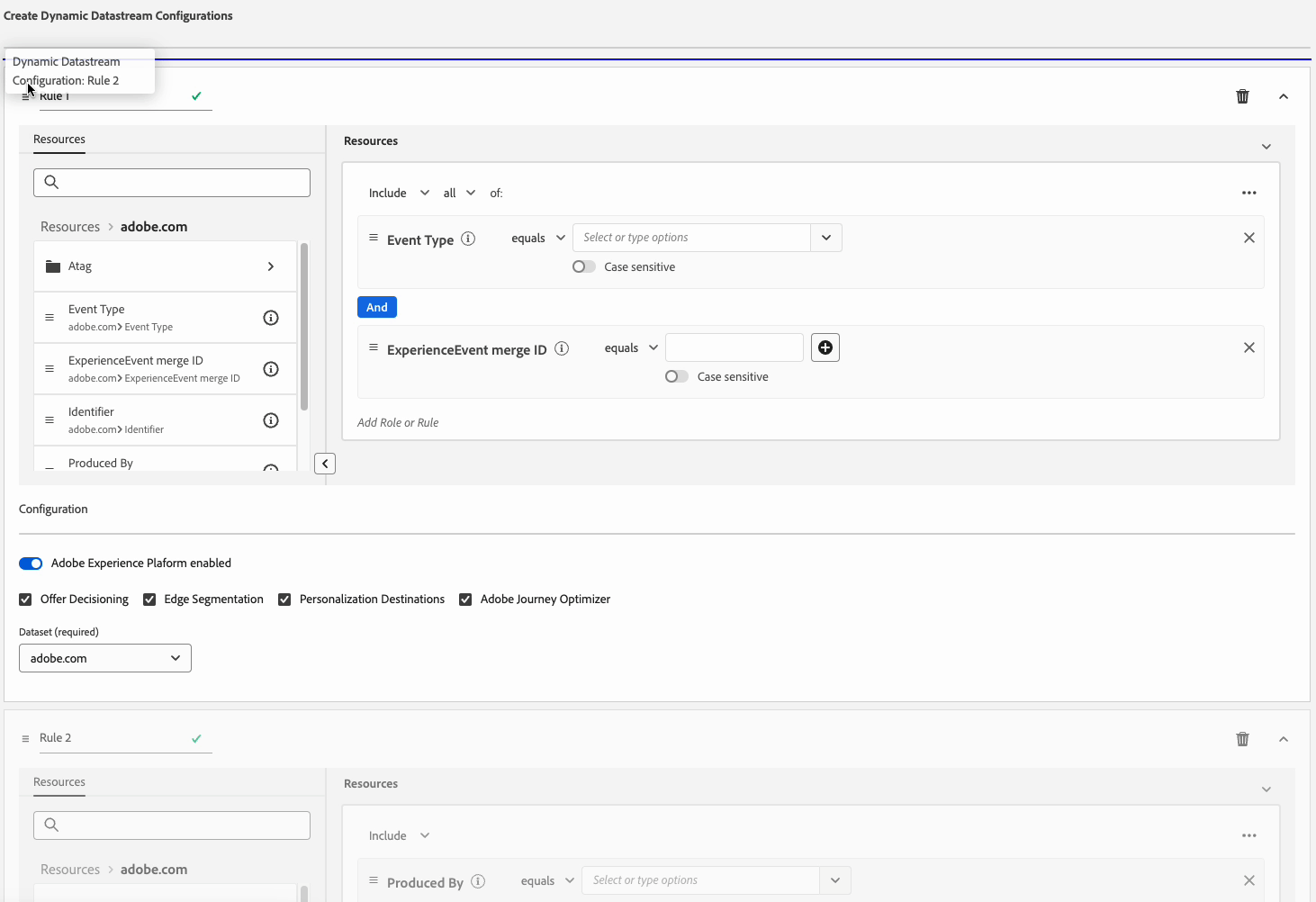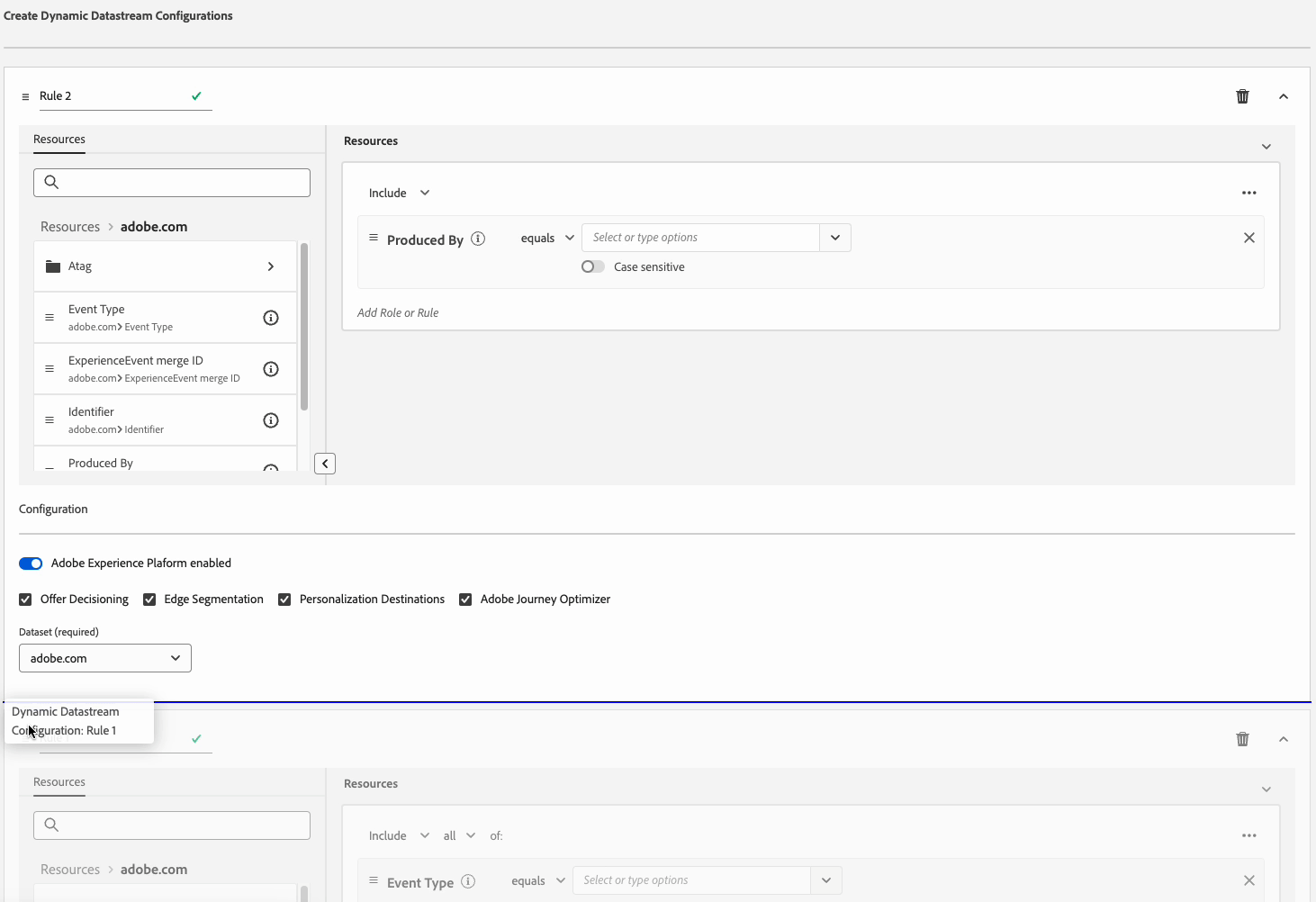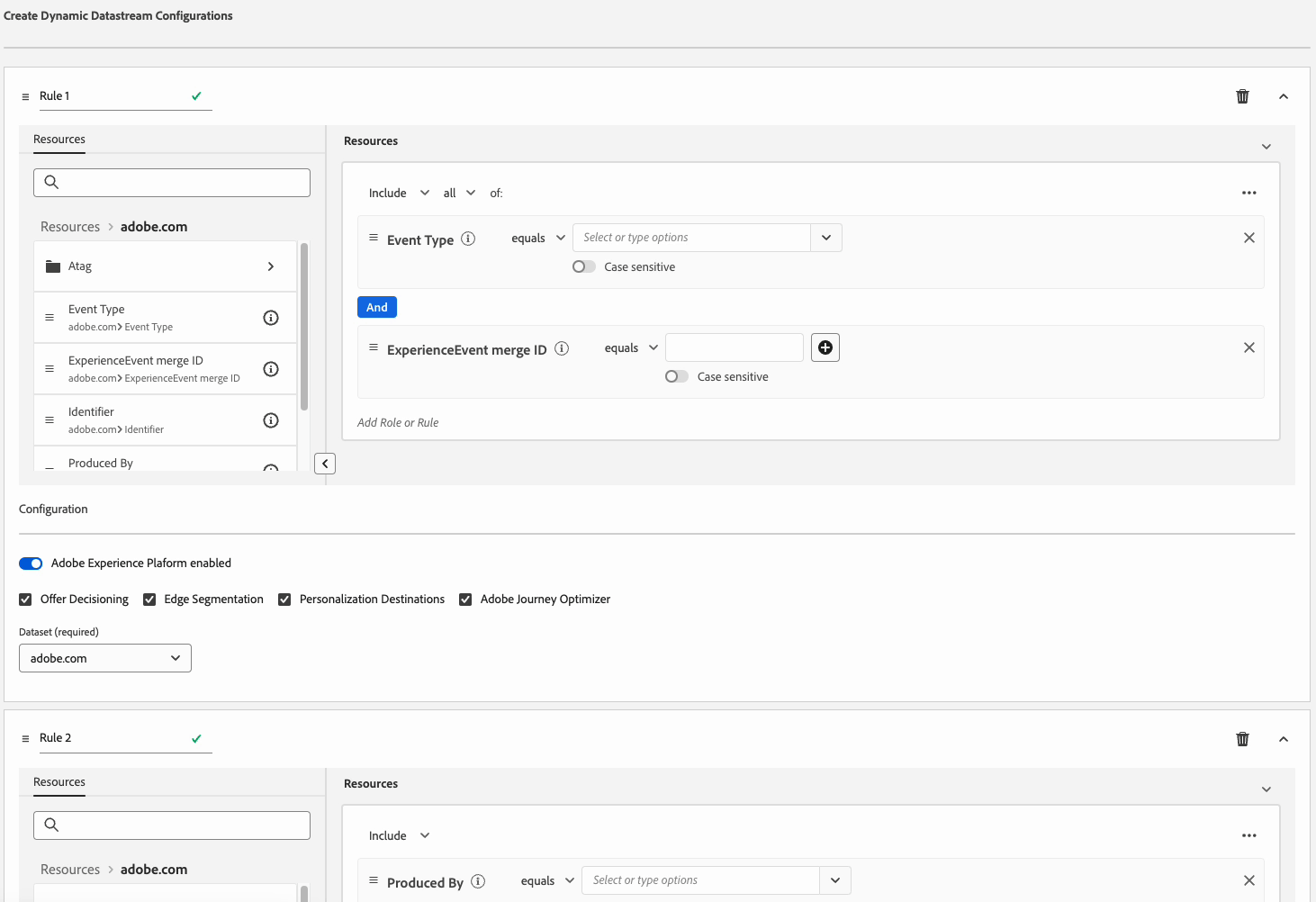
Crear un(a) Dynamic Datastream Configuration create-dynamic-configuration
Después de crear un conjunto de datos y agregarle un servicio, siga estos pasos para agregar una configuración dinámica al servicio.
-
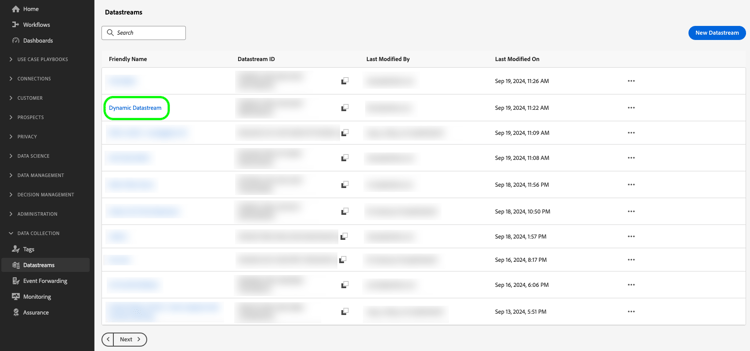
Vaya a la página Recopilación de datos > Flujos de datos y seleccione el flujo de datos que ha creado.
-
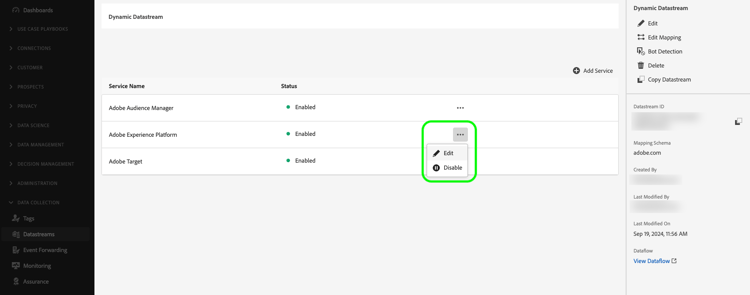
Seleccione la opción Edit en el servicio para el que desea definir una configuración dinámica.
-
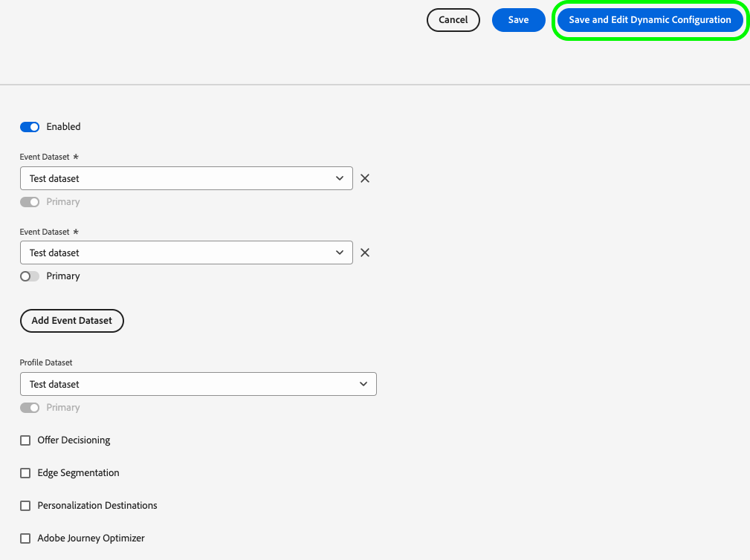
En la página Configurar, seleccione Guardar y editar configuración dinámica.
-
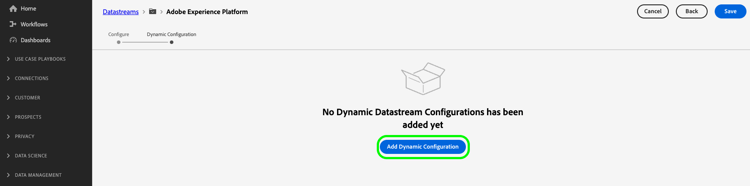
Seleccione Agregar configuración dinámica.
-
En el panel Recursos, arrastre y suelte los elementos con los que desee generar la regla en el lado derecho de la ventana. Puede combinar varios recursos para crear reglas complejas.
Use las opciones de cada recurso, como igual a, no es igual a, existe y más, para ajustar las reglas.
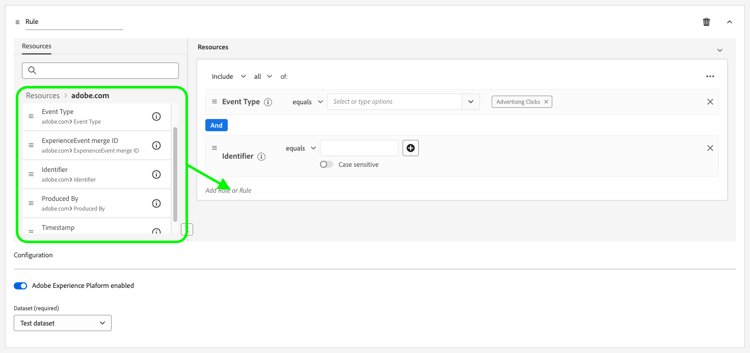
-
En la sección Configuración, habilite o deshabilite los servicios para cada regla, dependiendo de si desea que se envíen los datos a cada servicio. Si deshabilita un servicio, el enrutamiento se deshabilita y no se envían datos al servicio descendente.
Interfaz de usuario de
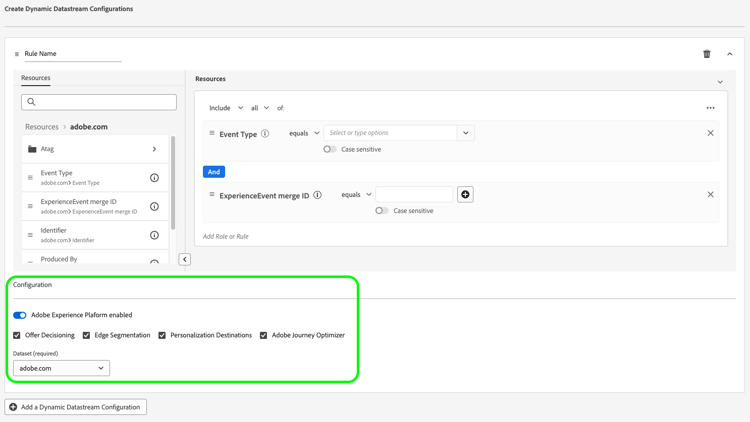
-
Cuando termine de configurar las reglas, seleccione Guardar.
Consideraciones de prioridad de reglas rule-priority
Puede definir varias reglas para cada Dynamic Datastream Configuration. Sin embargo, si los datos coinciden con las condiciones de varias reglas, solo se tendrá en cuenta la primera regla que coincida en la lista y el resto de reglas que coincidan se ignorarán.
Para lograr el comportamiento de enrutamiento de datos deseado, preste atención al orden en que organiza las reglas.
Para configurar el orden de las reglas, puede arrastrar y soltar las ventanas de reglas en el orden que desee.
Criterios de elegibilidad de regla eligibility-criteria
Las configuraciones de flujo de datos dinámico deben cumplir criterios de idoneidad específicos para garantizar un alto rendimiento y un enrutamiento fiable.
Tipos de datos admitidos supported-data-types
Las reglas de configuración de flujo de datos dinámico funcionan con tipos de datos específicos para garantizar un rendimiento óptimo y un enrutamiento de datos fiable. Comprender qué tipos de datos son compatibles le ayuda a crear reglas eficaces que procesan los datos de forma eficaz.
Operadores admitidos supported-operators
Las reglas pueden utilizar los siguientes operadores, según el tipo de datos:
equals, starts with, ends with, contains, exists, does not equal, does not start with, does not end with, does not contain, does not existequals, does not equal, greater than, less than, greater than or equal to, less than or equal to, exists, does not existequals true/false, does not equal true/falseequals, does not equal, exists, does not existtoday, yesterday, this month, this year, custom date, in last, from, during, within, before, after, rolling range, in next, exists, does not existINCLUDE, ANY/ALL (equivalente a AND/OR)Estructura de reglas rule-structure
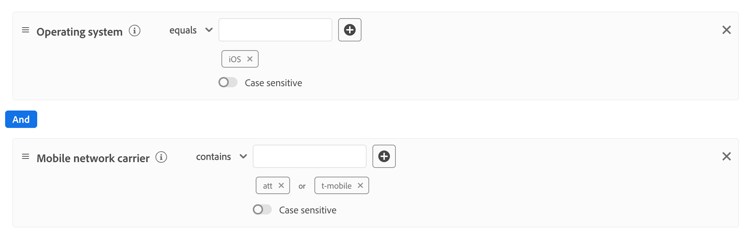
Las reglas deben ser expresiones lógicas planas. No se admiten expresiones lógicas anidadas (que usan contenedores o varios niveles de AND/OR). Si necesita lógica compleja, divídala en varias reglas planas.
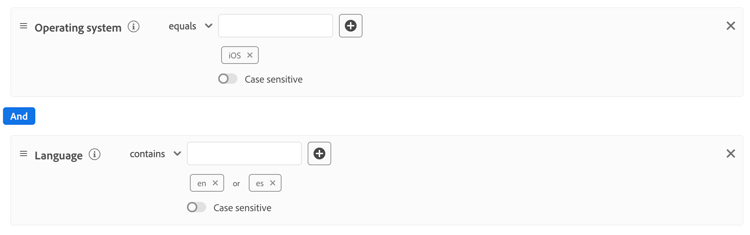
Por ejemplo, considere la siguiente regla compleja.
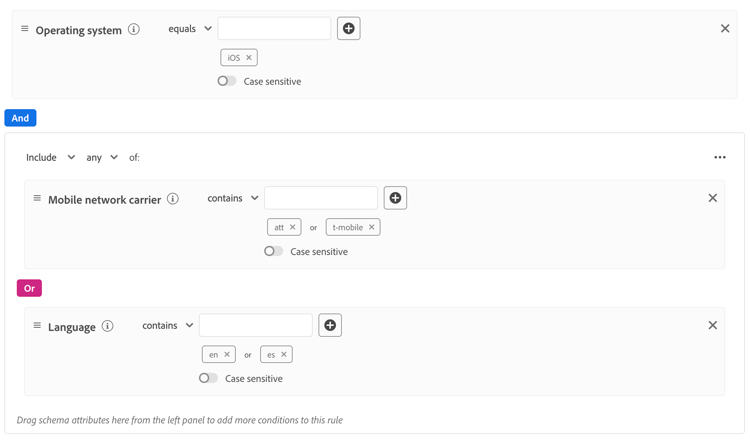
Puede dividir esta regla en las siguientes reglas más sencillas:
Próximos pasos
- Revise las prácticas recomendadas para Dynamic Datastream Configurations para el diseño de reglas, la estrategia de conjuntos de datos y las directrices operativas.
- Consulte Casos de uso de configuración de secuencia de datos dinámica para obtener configuraciones de reglas completas.
- Siga Probar y validar Dynamic Datastream Configurations para comprobar que las reglas se enrutan correctamente.