Effektiv big data-analys med hyperkuber
Lär dig hur du använder hyperkuber i Adobe Experience Platform Experience Query Service för att utföra avancerad dataanalys effektivare. I det här dokumentet beskrivs hur du använder avancerade funktioner från Apache Datasketches biblioteket för att hantera distinkta antal och komplexa beräkningar stegvis, utan att behöva bearbeta historiska data varje gång.
Vid big data-analys innefattar generering av mätvärden som distinkta tal, kvantifieringar, mest frekventa objekt, kopplingar och grafanalyser ofta icke-additiv räkning (där resultaten inte bara kan summeras från undergrupper). Traditionella metoder kräver ombearbetning av alla historiska data, som kan vara resurskrävande och tidskrävande. Använd skisser, som är kompakta sammanfattningar som använder sannolikheter för att representera stora datamängder, och avancerade Query Service-funktioner för att effektivisera processen genom att minska behovet av omberäkning.
Nyckelfunktioner för hyperkuber key-functions
Hyperkuber har flera kraftfulla funktioner som förbättrar effektiviteten och flexibiliteten i dataanalysen.
- Räkna unika användare eller distinkta frågor: Använd SQL-funktioner för att generera ett unikt antal användare som interagerar med olika datamängder, till exempel produktvisningar, platsbesök eller e-handelsaktiviteter, utan att behöva analysera rådata upprepade gånger.
- Inkrementell bearbetning: Utför inkrementella uppdateringar för att vika och sammanfoga datapunkter över dimensioner och tid utan att behöva beräkna om allt från början.
- Flerdimensionell analys: Hyperkuber möjliggör flerdimensionell filtrering och omsortering av data för att skapa sammanfattningsrader som representerar kombinationer av dimensioner. Dessa sammanfattningar kan sedan användas för att generera insikter med minimal beräkningsinformation.
Användningsexempel för hyperkuber use-cases
Använd hyperkuber för att effektivt generera distinkta räkningar för olika användarinteraktioner utan att behöva räkna om helt och hållet varje gång. Nedan följer några praktiska scenarier för hur de används:
- Analysera unika besökare som visar specifika produkter under en angiven tidsperiod.
- Identifiera användare som interagerar med flera produkter under en viss period för att förbättra korsförsäljningsanalysen.
- Skilj användare från hur de interagerar med en produkt men inte med en annan över tiden för att upptäcka olika inställningsmönster.
- Kombinera interaktionsdata online och offline för att få en heltäckande bild av användarbeteendet under en viss period.
- Spåra användarrörelser i olika aktiviteter i en händelse för att optimera layout och tjänster.
Fördelar med att använda hyperkuber
I dessa fall kan du förberäkna grundläggande information för specifika kategorier. När du analyserar data över flera dimensioner och tidsperioder måste du antingen beräkna om allt från rådata eller använda en frågetjänsthyperkub. Hyperkuber effektiviserar processen genom att organisera data effektivt, vilket möjliggör flexibel filtrering och flerdimensionell analys utan ombearbetning. De använder avancerade funktioner för att snabbt och exakt uppskatta resultaten och ger viktiga fördelar som förbättrad bearbetningseffektivitet, skalbarhet och anpassningsbarhet för komplexa analysuppgifter.
Datastorlekseffektivitet för frågebearbetning
Frågetjänsten kan komprimera miljoner eller miljarder datapunkter (till exempel användar-ID) till ett kompakt formulär som kallas skiss. Skissen har en betydligt mindre datastorlek för frågebearbetning, vilket gör att skalbarheten bevaras och gör det mycket enklare och snabbare att arbeta med. Hur stora originaldata än blir blir skissens storlek liten, vilket gör att stora data kan analyseras mycket mer hanterbart och effektivt.
Bilden nedan visar hur Commerce, produktinformation och ExperienceEvents för webbdimension behandlas i skisser, som sedan används för att beräkna unika räkningar.
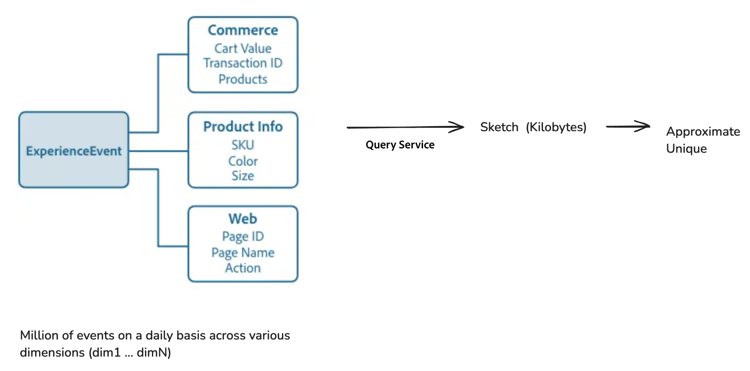
Sammanfoga skisser för snabbare och enklare dataanalys
Om du vill undvika att behöva beräkna om och förbättra bearbetningshastigheten kan du sammanfoga skisser från olika kategorier eller grupper. Frågetjänsten förenklar också designen genom att organisera data i en hyperkub, där varje rad blir en sammanfattning av dess partition (en samling dimensioner) bredvid skisskolumnen. Varje rad i hyperkuben innehåller dimensionskombinationen men har inga rådata. När du kör en fråga anger du de dimensionella kolumner som du vill använda för att skapa additiva mått och sammanfogar skisserna för dessa rader.
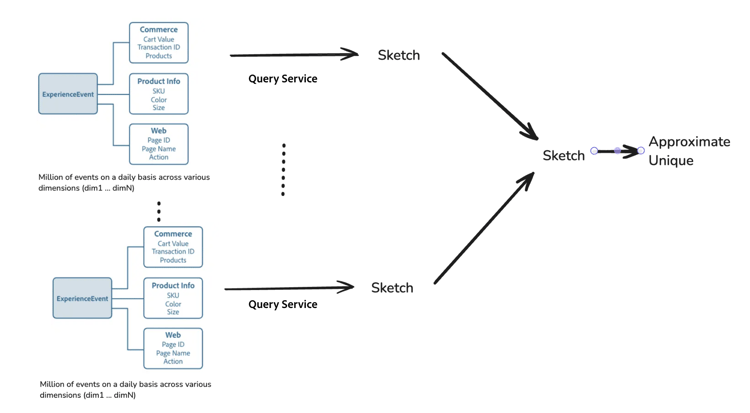
Kostnadseffektivitet cost-effectiveness
Kunddata är ofta storskaliga, men du kan eliminera behovet av att bearbeta om historiska data genom att använda stegvis bearbetning. Skisserna är mycket mindre och ger snabbare resultat i realtid samtidigt som du sparar på datorresurser och kostnader. Den här dataomvandlingen gör interaktiva frågor mer genomförbara och effektiva.
Funktioner - översikt
I det här avsnittet beskrivs hur varje funktion optimerar databearbetningen och förbättrar analysmöjligheterna genom effektiv användning av skisser och hyperkuber. Den beskriver deras syfte, till exempel syntax, parametrar och förväntade utdata.
Skapa unika uppskattningar av antal med HLL-skisser
hll_build_agg är en sammanställningsfunktion som skapar en HLL-skiss (HyperLogLog). Den här funktionen är en kompakt, sannolikhetsmetod för att beräkna antalet unika värden i en kolumn eller ett uttryck i en grupperad datamängd.
Funktionsdefinition
hll_build_agg(column [, lgConfigK])
Användning:
I följande exempel visas hur funktionen kan struktureras i en fråga.
SELECT
[dim1, dim2 ... ,] hll_build_agg(coalesce(col1, col2, col3)) AS sketch_col
FROM fact_sketch_table
[GROUP BY dimension1, dimension2 ...]
Parametrar
columnlgConfigKUtdata
sketch_resSQL-exempel
I följande exempel skapas en sammanställd skiss för kolumnen customer_id:
SELECT
country,
hll_build_agg(customer_id, 10) AS sketch
FROM
EXPLODE(
ARRAY<STRUCT<country STRING, customer_id STRING, invoice_id STRING>>[
('UA', 'customer_id_1', 'invoice_id_11'),
('CZ', 'customer_id_2', 'invoice_id_22'),
('CZ', 'customer_id_2', 'invoice_id_23'),
('BR', 'customer_id_3', 'invoice_id_31'),
('UA', 'customer_id_2', 'invoice_id_24')
])
GROUP BY country;
SQL-exempelutdata:
Beräkna distinkta antal med HLL-skisser
hll_estimate är en skalär funktion som ger en uppskattning av det distinkta antalet inom varje rad i en datauppsättning. Till skillnad från sammanställningsfunktioner arbetar hll_estimate radvis och används för att beräkna det distinkta antalet från en skiss inom enskilda rader.
sketch_count för aggregerade antal.Funktionsdefinition
hll_estimate(sketch_col)
Användning:
I följande exempel visas hur funktionen kan struktureras i en fråga.
SELECT
[col1, col2 ... ,] hll_estimate(sketch_column) AS estimate
FROM fact_sketch_table
Parametrar
sketch_columnUtdata
estimateSQL-exempel
I följande exempel beräknas det distinkta antalet kunder per land som använder funktionen hll_estimate i en HLL-skiss:
SELECT
country,
hll_estimate(hll_build_agg(customer_id, 10)) AS distinct_customers_by_country
FROM
(
SELECT
country,
hll_build_agg(customer_id, 10) AS sketch
FROM
EXPLODE(
ARRAY<STRUCT<country STRING, customer_id STRING, invoice_id STRING>>[
('UA', 'customer_id_1', 'invoice_id_11'),
('CZ', 'customer_id_2', 'invoice_id_22'),
('CZ', 'customer_id_2', 'invoice_id_23'),
('BR', 'customer_id_3', 'invoice_id_31'),
('UA', 'customer_id_2', 'invoice_id_24')
])
GROUP BY country
);
SQL-exempelutdata:
Sammanfoga flera HLL-skisser med hll_merge_agg
hll_merge_agg är en sammanställningsfunktion som sammanfogar flera HLL-skisser i en grupp och skapar en ny skiss som utdata. Det möjliggör en kombination av skisser över partitioner eller dimensioner, vilket ger större flexibilitet vid dataanalys.
Funktionsdefinition
hll_merge_agg(sketch_col [, allowDifferentLgConfigK])
Användning:
I följande exempel visas hur funktionen kan struktureras i en fråga.
SELECT
[dim1, dim2 ... ,] hll_merge_agg(sketch_column.sketch) AS estimate
FROM fact_sketch_table
[GROUP BY dimension1, dimension2 ...]
Parametrar
sketch_columnallowDifferentLgConfigKlgConfigK-värden sammanfogas. Standardvärdet är false. Ett undantag genereras om värdet är false och skisser har olika lgConfigK-värden.allowDifferentLgConfigK är inställt på false sammanfogas skisser med olika lgConfigK-värden i UnsupportedOperationException.Utdata
sketch_resSQL-exempel
I följande exempel sammanfogas flera HLL-skisser i kolumnen customer_id:
SELECT
hll_merge_agg(hll_sketch) AS uniq_customers_with_invoice
FROM
(
SELECT
country,
hll_build_agg(customer_id) AS hll_sketch
FROM
EXPLODE(
ARRAY<STRUCT<country STRING, customer_id STRING, invoice_id STRING>>[
('UA', 'customer_id_1', 'invoice_id_11'),
('BR', 'customer_id_3', 'invoice_id_31'),
('CZ', 'customer_id_2', 'invoice_id_22'),
('CZ', 'customer_id_2', 'invoice_id_23'),
('BR', 'customer_id_3', 'invoice_id_31'),
('UA', 'customer_id_2', 'invoice_id_24')
])
GROUP BY country
UNION
SELECT
country,
hll_build_agg(customer_id) AS hll_sketch
FROM
EXPLODE(
ARRAY<STRUCT<country STRING, customer_id STRING, invoice_id STRING>>[
('UA', 'customer_id_1', 'invoice_id_21'),
('MX', 'customer_id_3', 'invoice_id_31'),
('MX', 'customer_id_2', 'invoice_id_21')
])
GROUP BY country
)
GROUP BY customer_id;
SQL-exempelutdata:
Uppskatta kardinalitet med hll_merge_count_agg
hll_merge_count_agg är en sammanställningsfunktion som uppskattar kardinaliteten (antalet unika element) från en eller flera skisser i en kolumn. Den returnerar en uppskattning för alla skisser som påträffas i grupperingen. Den här funktionen används för att samla skisser och kan inte användas som en radvis omformning. Använd sketch_estimate för radvisa uppskattningar.
Funktionsdefinition
hll_merge_count_agg(sketch_col [, allowDifferentLgConfigK])
Användning:
I följande exempel visas hur funktionen kan struktureras i en fråga.
SELECT
[dim1, dim2 ... ,] hll_merge_count_agg(sketch_column) AS estimate
FROM fact_sketch_table
[GROUP BY dimension1, dimension2 ...]
Parametrar
sketch_columnallowDifferentLgConfigKlgConfigK-värden sammanfogas. Annars genereras ett UnsupportedOperationException.Utdata
estimateSQL-exempel
I följande exempel beräknas antalet unika kunder med fakturor som använder funktionen hll_merge_count_agg:
SELECT
hll_merge_count_agg(hll_sketch) AS uniq_customers_with_invoice
FROM
(
SELECT
country,
hll_build_agg(customer_id) AS hll_sketch
FROM
EXPLODE(
ARRAY<STRUCT<country STRING, customer_id STRING, invoice_id STRING>>[
('UA', 'customer_id_1', 'invoice_id_11'),
('BR', 'customer_id_3', 'invoice_id_31'),
('CZ', 'customer_id_2', 'invoice_id_22'),
('CZ', 'customer_id_2', 'invoice_id_23'),
('BR', 'customer_id_3', 'invoice_id_31'),
('UA', 'customer_id_2', 'invoice_id_24')
])
GROUP BY country
UNION
SELECT
country,
hll_build_agg(customer_id) AS hll_sketch
FROM
EXPLODE(
ARRAY<STRUCT<country STRING, customer_id STRING, invoice_id STRING>>[
('UA', 'customer_id_1', 'invoice_id_21'),
('MX', 'customer_id_3', 'invoice_id_31'),
('MX', 'customer_id_2', 'invoice_id_21')
])
GROUP BY country
)
GROUP BY customer_id;
SQL-exempelutdata:
Begränsningar
För närvarande kan skisser inte uppdateras när de har skapats. Framtida uppdateringar ger möjlighet att uppdatera skisser. Med den här funktionen kan du hantera missade körningar och sen inhämtning av data mer effektivt.
Nästa steg
Genom att läsa det här dokumentet vet du nu hur du använder hyperkuber och tillhörande skissfunktioner för att utföra effektiv databearbetning för komplexa flerdimensionella analyser utan att behöva bearbeta historiska data på nytt. Denna metod sparar tid, minskar kostnaderna och ger den flexibilitet som krävs för interaktiva frågor i realtid, vilket gör den till ett värdefullt verktyg för big data-analys i Adobe Experience Platform.
Utforska sedan andra nyckelbegrepp, som inkrementell inläsning och borttagning av datadubbletter, för att fördjupa din förståelse för hur du använder dessa funktioner effektivt för dina specifika databehov.